

پیش از آنکه به UTF-8 بپردازم لازم است تا اندازهای با سیستمهای کدگذاری رشتهها آشنا شویم.
تا زمانی نه چندان دور، بیشتر سیستمعاملها و کامپایلرهای برنامهنویسی با سیستم قدیمی ASCII کار میکردند. در این سیستم( سیستم اسکی ) هر نویسه( Character ) یک بایت یا هشت بیت فضا اشغال میکند. در نتیجه کل نویسههای قابل پوشش در این سیستم ۲۵۶ حرف خواهد بود.
نیازی به توضیح نیست که این ۲۵۶ حرف برای نگهداری نویسههای زبانهای مختلف و حتی برای برخی از زبانها به تنهایی کافی نیست.
ممکن است برایتان سوال پیش بیاید که با این حجم اندک چگونه ممکن است بتوانیم رشتههایی با زبانهای مختلف را در کنار هم داشته باشیم.
راه حل تعریف شده در سیستم اسکی عبارت بود از تعریف یک کدپیج( Code Page ) در کنار هر رشته یا در کنار هر نرمافزار یا به صورت پیشفرض درون سیستمعامل.
کدپیج مشخص میکند که تعداد محدود نویسههای ASCII به چه زبانی اختصاص یافتهاند. با این شیوه میتوان مشخص کرد که از نویسهی شمارهی ۱۲۸ تا ۲۵۵ به زبان فارسی اختصاص دارد و پس از آن یک متن فارسی را در کنار یک متن انگلیسی درج کرد.
حتی با این راه حل امکان استفاده از زبان فارسی و آلمانی در یک رشته ممکن نیست.
یونیکد
برای حل این مشکلها، سیستم جدیدی به نام یونیکد( Unicode ) به تصویب رسید و به آرامی جایگزین سیستم قبلی ASCII شد.
سیستم جدید برای نگهداری هر نویسه از دو بایت یا ۱۶ بیت فضا استفاده میکند. به عبارت دیگر اگر رشتهای با ۳۰ نویسه را بخواهیم در سیستم کدگذاری یونیکد ذخیره کنیم، به ۶۰ بایت فضا نیاز خواهیم داشت.
در تعریف هر استاندارد جدید، مشکلهای جدیدی نیز پدیدار میشوند. در مورد استاندارد یونیکد هم همین مشکل به وجود آمد و آن عدم سازگاری نرمافزارهای قدیمی با سیستم جدید بود. نرمافزارهای قدیمی که با سیستم ASCII کار میکردند، چنانچه فایلی با سیستم یونیکد را باز میکردند هر نویسه را که دو بایت فضا اشغال کرده بود به دو قسمت تقسیم میکردند و از خواندن متن اصلی عاجز بودند.
یوتیاف-۸ یا UTF-8 چیست؟
برای حل مشکل سازگاری نرمافزارهای قدیمی شیوهی جدیدی از کدگذاری یونیکد ابداع شد. در این شیوه که UTF-8 نام دارد، طول هر نویسه بر خلاف سیستم یونیکد و سیستم ASCII ثابت نیست. در سیستم UTF-8 هر نویسه میتواند از یک تا چهار بایت فضا اشغال کند.
نویسههایی که شمارهی آنها کوچکتر از ۱۲۸ باشد، یک بایت، و به ترتیب هرچه شمارهی نویسه بزرگتر باشد،از دو تا چهار بایت فضا ممکن است به اشغال درآید.
در این سیستم، علامتهای برنامهنویسی و نویسههای زبان انگلیسی مشابه سیستم ASCII نگهداری میشوند و نویسههای زبانهای دیگر که شمارههایی بیش از ۱۲۷ دارند فضای بیشتری اشغال خواهند کرد.
BOM
BOM یا Byte Order Mark ترکیبی است از چند نویسهی ویژه که قرارگیری آن در ابتدای یک فایل متنی، نوع کدگذاری نویسههای موجود در آن فایل را مشخص میکند. BOM بخشی از متن فایل به حساب نمیآید و وجود آن تنها برای رفع ابهام از نوع و شیوهی کدگذاری نویسههای یک فایلی متنی ضروری است.
با توجه به اینکه سیستم UTF-8 برای رفع مشکل سازگاری یونیکد با سیستم ASCII توسعه یافته است، در بیشتر مواقع از درج BOM مخصوص به UTF-8 در ابتدای فایلها خودداری میشود. زیرا این علامت میتواند باعث ایجاد سردرگمی برای ویرایشگرها و کامپایلرهایی شود که آن را نمیشناسند.
عبارتهای UTF-8 Without BOM، UTF-8 w/o BOM یا به طور ضمنی UTF-8 که در ویرایشگرهای متنی به نمایش درمیآیند، نشاندهندهی عدم وجود BOM در ابتدای فایل UTF-8 هستند.
کاربرد UTF-8
استفاده از نویسههای زبانهای مختلف در کامپایلرهای و مفسرهای برنامهنویسی مانند PHP که با سیستم ASCII کار میکنند، از مهمترین کاربردهای سیستم UTF-8 است. با توجه به اینکه دستورات این زبانها در محدودهی نویسههای کمتر از ۱۲۸ قرار میگیرند، عملکرد صحیح این مفسرها و کامپایلرها تضمین میشود. به دلیل اینکه نویسههای چندزبانه درون علامتهای گیومه یا آپستروف قرار میگیرند، در ارسال آنها به خروجی نیز اشکالی به وجود نمیآید.
اشکالهای UTF-8
استفاده از سیستم UTF-8 بدون هزینه نیست. نخستین هزینهی ایجاد شده در این سیستم، حجم پردازش اضافی برای تبدیل نویسههایی با طول ثابت به نویسههایی با طول متغیر است. ویرایشگر متنی هنگام بازکردن چنین فایلی، بار پردازشی مضاعفی برای شناسایی طول هر نویسه و تبدیل آن به کد متناظر انجام میدهد.
مشکل دوم، عدم امکان تشخیص طول رشته است. با توجه به آنچه در مورد متغیر بودن طول نویسهها گفته شد، تعیین طول رشته از روی بایتهای تشکیلدهندهی آن ناممکن است. و تنها راه حل پردازش کل متن از ابتدا تا انتها برای شمارش تعداد واقعی نویسهها است.
و مشکل سوم حجم اتلاف شده برای نگهداری نویسهها است. نگهداری متن با سیستم UTF-8 مستلزم اتلاف بخشی از بایتهای مفید جهت تعیین محدودهی هر نویسه است که این موضوع خود میتواند مورد توجه قرار بگیرد.
تبدیل UTF-8 به Unicode
سیستمعامل ویندوز دستوراتی برای کارکردن با این نویسهها در اختیار برنامهنویسان قرار میدهد. تابع MultiByteToWideChar برای تبدیل عبارتهای UTF-8 به یونیکد و تابع WideCharToMultiByte برای تبدیل رشتههای یونیکد به UTF-8 کاربرد دارد.
یک نمونه از بهکارگیری تابع MultiByteToWideChar را در ادامه مشاهده میکنید
MultiByteToWideChar( CP_UTF8, 'سیستم مبدا MB_ERR_INVALID_CHARS, 'پارامترهای تبدیل @arrFileContents(0), 'متن یوتیاف ۸ sizeof( arrFileContents ), 'طول متن ورودی @strFaFileContents, 'فضای ذخیرهسازی متن خروجی sizeof( strFileContents ) 'مقدار فضای تخصیص داده شده برای خروجی ) |
مثال برای تبدیل رشته در php
$utf16_string = iconv( 'UTF-8', 'UTF-16LE//IGNORE', $utf8_string ); |
زیرساخت فنی UTF-8
همان گونه که گفته شد، نویسههای UTF-8 از یک تا چهار بایت فضا اشغال میکنند. شکل تخصیص فضای این بایتها بر اساس طول بیتهای نویسه متغیر است و چند بیت اختصاصی هر بایت برای علامتگذاری استفاده میشود.
نویسههای یک بایتی:
نویسههایی که شمارهای کمتر از ۱۲۸ داشته باشند به صورت طبیعی دارای بیت نخست صفر هستند:( علامت b به معنی بیت قابل استفاده است )
0bbbbbbb
نویسههای دو بایتی:
نویسههایی در محدودهی ۱۲۸ و ۵۷۲۷۹ به صورت زیر ذخیره میشوند:
110bbbbb 10bbbbbb
نویسههای سه بایتی:
نویسههایی در محدودهی ۵۷۲۸۰ و ۱۵۷۱۲۱۹۱ به صورت زیر ذخیره میشوند:
1110bbbb 10bbbbbb 10bbbbbb
نویسههای چهار بایتی:
نویسههایی در محدودهی ۱۵۷۱۲۱۹۲ و ۴۱۵۶۵۳۸۸۱۵ به صورت زیر ذخیره میشوند:
11110bbb 10bbbbbb 10bbbbbb 10bbbbbb
UTF-8 و عبارتهای منظم
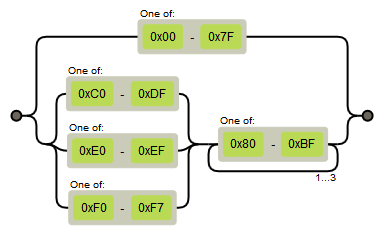
استفاده از عبارتهای منظم یا Regular Expression برای پیدا کردن یک نویسهی UTF-8 امکانپذیر است.
یک شکل سادهشده برای شناسایی این نویسهها را در ادامه مشاهده میکنید:
/[\x00-\x7f]|(?:[\xc0-\xdf]|[\xe0-\xef]|[\xf0-\xf7])[\x80-\xbf]{1,3}/ |
بسیار عالی…
واقعا همچین مطلب برای تازهکاران و سرسریگیران لازم بود…
موفق باشید.

خیلی ممنون
لطف دارید
بسیار عالی و مفید .
مطلب خوبی بود. خسته نباشی.
در مورد Little endian و انواع دیگه هم اگر می نوشتی کامل تر می شد.
در کل ممنون
با سلام و سپاس
به دلیل اینکه مطلب در خصوص UTF-8 بود و وارد شدن به جزئیات یونیکد ممکن بود از حوصلهی خواننده خارج شود سعی کردم از یونیکد و جزئیاتش مثل Little Endian و Big Endian صرف نظر کنم
ممنونم بابت پست خوبتون ؛ واقعن لذت بردم …
با سلام وعرض خسته نباشید.
برای آپدیت کردن یکدستگاه dvd از نمایندگیش در خواست فایل آپدیت کردم یک فایل با فرمت utf-8 برایم ایمیل
کرده برای اینکه این فایل رو تبدیل به هگز کنم تا بتونم دستگاه رو آپدیت کنم چکار باید بکنم. کد ارسالی رو ضمیمه
کردم. لطفا” راهنمایی کنید
با سلام
متاسفانه بنده چیزی از این اطلاعات که فرستاده بودید نمیدونم
حدس میزنم یک نرمافزار برای ریختن اطلاعات روی دستگاه یا با کمک ذخیره کردن این اطلاعات روی یک فایل و قرار دادنش روی حافظهUSB بشه این اطلاعات رو به دستگاه منتقل کرد
سلام
اطلاعات خوبی ارائه کردید
ممنونم
اما خیلی خوب میشود که یک منبع جامع تر نیزدر مورد مواردی که فرمودید از آن ها صرف نظر کردید
اعلام بفرمایید
متشکرم
با سلام و سپاس
یونیکد نکتههای خیلی زیادی دارد که معمولا دانستن تمام آنها مورد نیاز نیست
اگر با زبان انگلیسی آشنایی داشته باشید میتوانید بخشهایی از این مقالهی ویکیپدیا را برای اطلاعات بیشتر مطالعه کنید
بنده پیشنهاد میکنم در مورد نشانههای rlm و lrm جستجو بفرمایید که در زبان فارسی کاربرد زیادی دارند و بسیاری از برنامهنویسان چیزی از آن نمیدانند
سلام.
ممنون از مطلبتون. من برای ترجمه از gettext استفاده کردم. (فایل ها PO و MO)
سایت قرار است از فارسی به عربی ترجمه بشه.
روی wamp همه چیز درست است. اما روی سرور ترجمه به این صورت در میاد:
������
زیاد هم سرچ کردم. به نتیجه ای نرسیدم.
آیا شما میدونید مشکل از کجاست؟
متن بالا نیاز به یونیکد ISO-8859-6 داره اما من نمیخوام ازش استفاده کنم و از UTF-8 میخوام استفاده کنم.
ممنونم.
با سلام
فکر میکنم فایلهای ترجمه را با کدگذاری utf-8 ذخیره نکردهاید
لطفا اگر این مطلب «آشنایی با برنامهنویسی چند زبانه و شیوهی بهکارگیری gettext» را هم مشاهده نکردهاید، آن را مطالعه کنید
مشکل حل شد.
برای سایر دوستان میزارم که به این مشکل بر میخورن:
سلام و خسته نباشید
وقتی سایتمو روی هاست آپلود کردم بعد از تگ body این حروف نامفهوم میاد

چیست آیا!؟
روی لوکال نیست فقط تو هاست :/
با سلام
به احتمال زیاد یکی از فایلهای شما همراه BOM ذخیره شده است که در فایلهای تحت وب این علامت باید از فایل حذف شود
اگر از CMSهای مشهور استفاده میکنید، یکی از فایلهایی که خودتان ویرایش کردهاید ممکن است به این صورت ذخیره شده باشد
سلام. من یک برنامه جمع و جور حقوق و دستمزد برای یک شرکت نوشتم. برای تولید فایل تامین اجتماعی با فرمت text دچار مشکل شدم. که فکر میکنم بخاطر encoding داده ها باشه. اطلاعات توی دیتابیس utf8 ذخیره شده. میخواستم بپرسم میشه این اطلاعات را توی فایل خروجی به ascii ایران سیستم (فرمت مورد استفاده در فایلهای تامین اجتماعی) تبدیل کرد؟
انواع
(iconv(“UTF-8″,”ASCII”,$str ,
(iconv(“UTF-8″,”CP437″,$str ,
(mb_convert_encoding($str,”UTF-8″,”CP437″ , … را هم آزمایش کردم، ولی بیفایده بود. البته setlocale را تنظیم نکردم. ممکنه راهنمائی بفرمائید؟
با سلام
تا جایی که خاطرم هست، کدگذاری «ایرانسیستم» مربوط به سیستمعامل داس باید باشه و با کدگذاری ASCII در ویندوز و پایگاه داده متفاوته
برای انجام این تبدیل خودتون باید دست به کار بشید و حروف فارسی رو به کدهای متناظر در این سیستم تبدیل کنید
با جستجو به احتمال زیاد بتونید جدول تبدیل نویسهها رو پیدا کنید
با تشکر
خیلی جالب بود برام
مرسی
سلام.
ممنون از مطلبتون
من یه مشکل در برنامه ای که نوشتم دارم که مربوط به کاراکترهای خاصه . میشه راهنماییم کنید:
برنامه ای نوشتم که از سورس یک وب پیج، اسمی رو درمیاره و در دیتابیس ذخیره می کنه
مشکل: مسئله اینه که چون این اسم رو از سورس کد درمیاره ، در بعضی مواقع، یونیکد کاراکترهای خاص رو بر می گرونه
مثلا بجای – اینرو بر می گردونه ۲۵E2 2580 2593
یا مثلا بجای é اینرو بر می گردونه ۲۵C3 25A9
میشه راهنماییم کنید؟
با سلام
در HTML امکان استفاده از HTML Entity یا کدهایی که به یک حرف تبدیل میشوند وجود دارد.
یا باید از کتابخانهای استفاده کنید که این تبدیلها را برای شما انجام دهد یا خودتان برنامهی آن را بنویسید
سلام. لطفا میشه بگید که توی html عبارت charset=”UTF-8″ چه معنایی داره؟ اینو خیلی جا ها دیدم اما برام نا مفهوم بوده.
با تشکر از از مطالب عالیتون
با سلام
این کد به مرورگر میگوید که اطلاعات ذخیره شده در فایل فعلی با فرمت utf-8 هستند و با فرمت ascii ذخیره نشدهاند
بسیار ممنون از مطلبتون. سوالاتی که از توضیحات موجود تو منابع دیگه خونده بودم رو به درستی باز و قابل مفهوم کرد.
اگه امکانش هست پستی هم در مورد یونیکد قرار بدید.